This post was originally published at Walking the Wires
At Delacor we often talk about programming style, and I like to refer to Fab’s style as “defensive programming”. The overwhelming theme in her code is focussed on robustness and avoiding, wherever possible, the opportunity for things to go wrong. Over the past few years this has resulted in several internal “tips & tricks” for avoiding potential issues.
Allow me to introduce The Safe Programmer’s Corner. Here you will find articles aimed at making you a safer, more robust programmer.
We hope you like our idea.

I remember as a child sticking playing cards to the spokes of my bicycle wheels because they made this cool sound. It turns out that one of my friends didn’t feel it was so cool and decided that one day he should knock them off with a stick…………..whilst I was riding the bike………….at speed.
The feeling of going over the handlebars and the pain of hitting my head on the ground comes back to me occasionally. Usually prompted by seeing something like this:
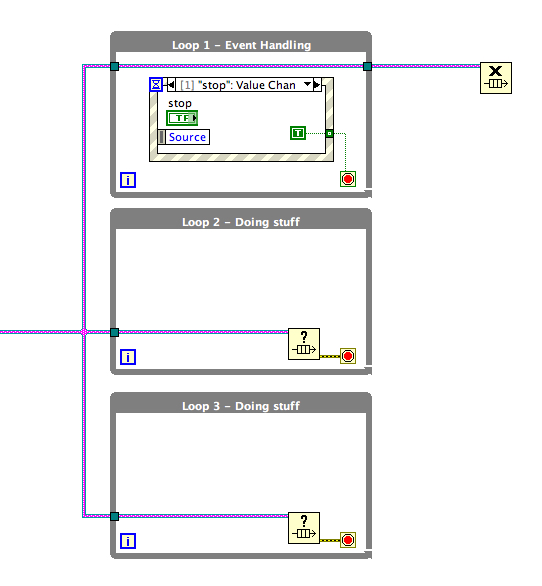
We have three While loops executing in parallel. The termination mechanism for two of the loops is provided by monitoring the status of a queue. The queue may or may not be used as a data transport mechanism elsewhere, but for two of the loops it is purely providing a stopping mechanism.
The code uses the error out terminal of the Get Queue Status primitive to stop execution on error. If the queue has been destroyed elsewhere, then the Get Queue Status primitive will return an error and stop the loop. Destroying the queue in a single location becomes the way of stopping multiple loops (which may or may not be executing on the same block diagram).
This is great, right? No need for Local or Global Variables, and no need to code up some other elaborate stopping mechanism. Maybe so, but many times I see the above construct result in unwanted behaviour. It is a blunt instrument, because we have a globally accessible stop that halts the entire application with no way to trace who did the halting (this isn’t going to be fun debugging at 2am!). The queue is not private and could be shared through the hierarchy, so anyone can choose to destroy it.
The person writing the application is choosing to destroy a queue and not specifically taking action to stop the application. It is simply a side effect that destroying the queue stops the application. If we need code in loop 3 that executes on close, we need to check for the error and ensure that the error code is 1 (queue destroyed).
This all feels a little like jamming a stick in the wheels.
The biggest mistake I see developers make is failing to call the Destroy Queue primitive, either literally through coding omission or procedurally through program execution, causing the call to never actually happen. In addition, a single developer might know that his intention was to stop the application this way. What happens if this code is later supported by a team or by a different developer? How are they supposed to know this was the original intention?
Instead I prefer that a developer creates and sends a dedicated Stop message. Something like this (although I don’t claim that this is in anyway a complete architecture) where the Stop message is a dedicated message that has been coded specifically to stop the application.

I know that this block diagram is somewhat more complex than the earlier example, but it is more scalable and robust than our original code.
We may choose to execute repetitive code in the timeout case of the event handlers (once I’ve added a timeout!)
To make the code more robust, we can wrap the event creation in a modified FGV (Functional Global Variable) as shown below, lets call it Obtain Stop.vi. Now it is possible to have all of those loops executing in separate VIs (yes there’s a caveat as to who should destroy the event, see here for more details on that).
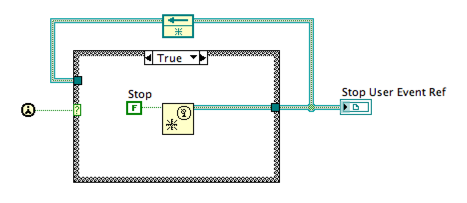
We can now wrap our event generation code in a subVI, lets call it Send Stop.vi. It will call our Obtain Stop.vi and it probably looks something like this:

We now have a way to search for every location where we might be stopping our application by searching for the above VI.
Finally we need to destroy our stop event when our loops stop running. Similarly to the Send Stop.vi we can call Obtain Stop.vi and then destroy the returned reference.
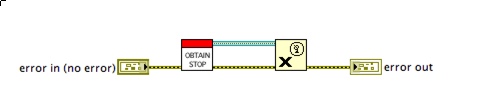
Now we have a block diagram that looks something like that shown below (click on the image to expand):

For an even more robust and scalable solution, take a look a the DQMH project template, where the application main VI stops all of the modules in the exit case.
I must also say that there are other extremely robust frameworks out there that use the destroy queue behaviour to stop the execution of loops however mostly their queues are being used as a message transport mechanism and the stop behaviour is simply a bi-product of that. Additionally these are message based architectures where the sending of a message can be traced within the hierarchy.
For example, in Actor Framework the code that sends the stop is in its own VI and the code that receives the stop is the same code that is already receiving other messages.
I hope this short post provokes some thoughts. Do you use the destroy queue method for stopping loops? How does it work for you? Have you come across this design pattern in the wild?
As always, we welcome your thoughts and feedback on this or any of the material we talk about.
Wire safely folks!
Chris

My main thought is “do not use a global stop”, period. Parallel loops should be organized in a tree-like hierarchy. For example, one “top level” loop may be in charge of several “module” loops, that each may have their own “submodules”, who may have “helper” loops, etc. There should be no global signals of any kind. The top-level can tell its modules to shutdown, but each module should be responsible for telling its submodules to shutdown. Each “branch” of the tree has it’s own shutdown procedure, and can choose to do a phased or controlled shutdown of its subloops if it decides.
James,
Thanks for that input. Yes to some extent I agree unfortuantely the tree-like structure you describe is not what I see what I visit other organisations. I see lots of parallels loops, more often than not on the same block diagram.
In your solution does the top level loop wait for any kind of acknowledgement from the submodules or helper loops to know that they’ve shutdown successfully?
Chris
I agree with James 99.99%. I might use a global stop for convenience in a very small & simple app, where troubleshooting is not an issue. I’m talking about the talking the kind of code one might bang out in 20 minutes to complete a minor, temporary task. Deployed apps that other people use or may support, absolutely.
Also, I would never use an error mechanism as a stop anywhere, even within a self-contained module. It can trigger a stop, but not be the cause of one. It irks me when I see it.
Todd,
Thanks for joining the discussion. I think we are all in broad agreement here. What is it specifically that “irks you”? Have you come across applications which use such a mechanism to stop, out in the wild?
I think what James proposes is extremely sound. Many systems have a natural hierarchy where there’s some top level module that calls into a number of lower level modules directly, these in turn have their own hierarchy of modules they call. Cascading the Stop mechanism in this tree like structure makes a lot of sense.
Chris
The “stop due to the destroyed queue” is very common because NI uses it in their Producer/Consumer example. And it does irk me to no end.
My prime example is a logging system. Have one loop reading data from a DAQ and another loop is taking the data and logging it to disk. Using NI’s example, when the producer is done, the queue is destroyed, which stops the consumer. This is fine except that whatever is left in the queue when it is destroyed is lost forever. In many of the systems I have done, I cannot afford to lose any data.
So long story short, if using a queue, the loop that consumes the data should be the one that destroys the queue. A message should be sent via the queue telling the loop to stop, allowing for a proper shutdown.
Tim,
That’s a great point right there regarding the potential loss of data. I knew I had seen the construct of “Stop due to destroyed queue” somewhere, thanks for pointing out that it was in the Producer/Consumer shipping examples.
Chris
I agree and would offer for the applications I create, that is running equipment. That the “Shutdown” takes the form of a Queue *request* [command] to each thread [State Machine] where the shutdown of the particular sub-system and subsequent clean-up and shutdown hardware states are managed by those individual tasks. Simply pulling the plug on the queue is not an ideal option.
For me, the nature of taking exception to some implementations – lies in when users expand upon using such techniques for larger projects – where the weakness of these implementations – cause unforeseen problems. Aggravated by long time ‘successful’ use of these techniques – until their weakness crop up /after many hours of debug and heartache.
Therefore; I recommend new users simply avoid them.