This post was originally published at Walking the Wires

This is a post I have been wanting to write for a long time, not to share some technical nuance or promote some new product, but because of the philosophical debate that I hope it promotes. It is something I have wondered about for several years, and my viewpoint on it has shifted several times. In fact, my opinion has recently changed again. It’s time to talk to others and get some consensus of opinion.
So diving straight into the issue with a rhetorical question:
Is it good LabVIEW programming practice to pass a reference, cluster or class through a SubVI if that SubVI is only consuming the data and not modifying it in any way ?
There, I’ve said it, now discuss!
Before the floodgates open, let me explain my reason for asking the question and put my point across. Consider the image below:
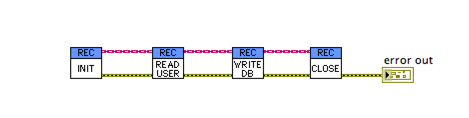
This is something comfortable and familiar. Something that we are used to seeing daily in our LabVIEW code; a common thread being passed amongst members of a library, or in this case a LabVIEW class.
However, looking at the code above it’s not obvious what (if any) action the Write DB VI or Read User VI is performing on the class. Is it writing data to the class, consuming data or both ? If I am experiencing problems related to the data in the class not being as expected at a later point downstream, then I need to dig inside each VI to see what it’s doing as part of my debug process.
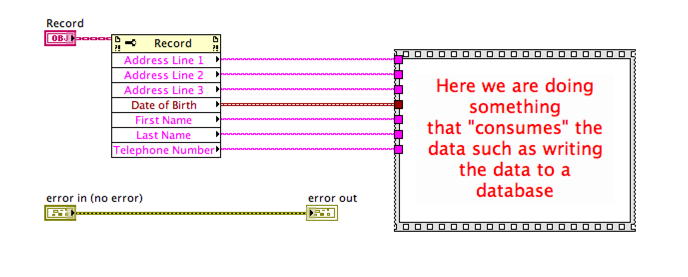
Inside the Write DB VI I see the following:

As you can see, we are simply consuming the data, accessing the class data and writing it to a database. The passing through of the class is not required and yet what happens if we don’t do this?
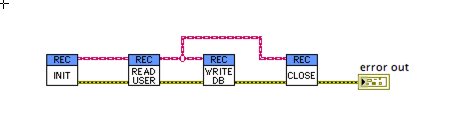
I may be stuck in my ways but this looks incomplete, and the calling code “looks” even worse!
Now, I’m nothing if not pragmatic.
Let’s take a step back. Neat and tidy it may not be, but the diagram above conveys significantly more information. I can now see at a glance that the Write DB VI is merely a consumer of the data. If the values in my class are incorrect, I know that I don’t need to look inside that VI to find the cause. I have now improved the quality of information described by my block diagram and let’s not forget that this is the reason why we use LabVIEW in the first place. I have made debugging easier, and as much as it sets my OCD on high alert, that extra junction in the wire tells me what I need to know.
I don’t like it (but could probably get used to it)…..however “pretty is as pretty does”.
Does it matter what the class private data consists of? If the class contains references such as a VISA refnum, does this affect the decision to pass through data?
Again consider the following construct:
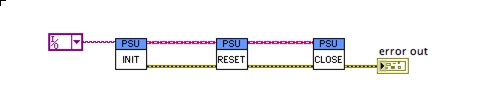
We have no idea how the Reset VI is operating upon the class. We need to look inside to see if it is modifying the private data.
Inside we see the following:
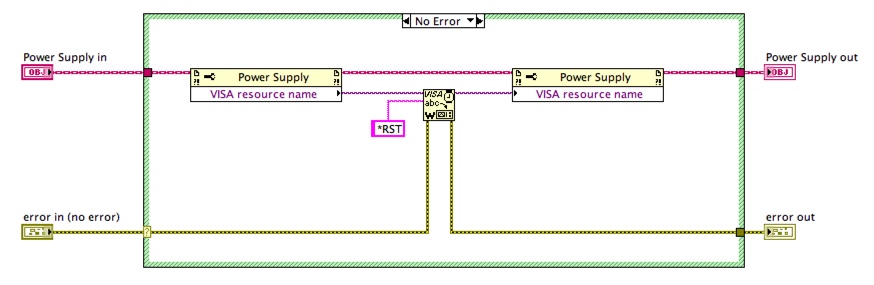
The rebuilding of the VISA refnum and the passing through of class data is redundant, but the alternative makes me somewhat uncomfortable.
Some of this discomfort goes way back to when I was first getting started with LabVIEW, when my college Professor had the mantra “wire every Serial / GPIB reference through EVERY VI.“ This guy would literally pull the power lead out of your PC if he caught you not doing this. Maybe I just got tired of re-booting Windows 3.1, but the message stuck.
Speaking to others who have run into issues with virtual COM ports and the like, the concept of not wiring a reference straight through makes them nervous; it’s like a comfort blanket for them.

So now it’s over to you to consider the following:
Is it more or less readable to pass the class through? What do we mean by readable anyway? Are we talking about “form over function” here?
As we have seen, not passing a wire through a Sub VI can actually provide more information, but it goes against the common style that most of us are familiar with and which is promoted in countless example programs and by NI themselves in their training manuals and style guide documentation.
I’d love to hear your thoughts on the matter, so please leave your comments.
Happy wiring,
Chris
…and by the way, whether or not you should actually use the error case structures in the examples above is a topic for another blog post.

I’m going to get in quick on this.
From my perspective as someone that is heavy on OO development, as long as the class or cluster is relevant I will always pass it through.
Why? To not makes an external assumption about the internal implementation. What if in the future we need to modify a pointer, now our external code has to change due to an internal modification. I see this as a necessary evil of by-value OO.
I’m pragmatic and I do like that you would know exactly what modifies it and it does make it clearer about the effect of forking the wire, but my preference is for passing it through.
If a sub VI passes data from input to output without modifying the data, I usually prepend the output terminal name with “dup” (duplicate). For example, in your last example, the input terminal would be “Power Supply in” and the output terminal would be “dup Power Supply in”. In my opinion, this clearly conveys that the sub VI did not modify the data and keeps the calling VI’s diagram clean and neat.
Mark,
The risk with this approach is later on if you decide to add data to be bundled to the output and forget to change the name of the output (remove the dup), the output is lying.
This is the same argument I hear over and over from developers who chose not to add free labels with comments, because it can become stale. I still add documentation and I think it is fine to still add the dup to the output.
I am very observant about changing documentation when I change code, but I can tell you I have missed a few myself. So as long as you are aware of the risk , then this is a fine approach. Perhaps you could create a VI Analyzer test that would warn you if an output terminal is called dup, but it is no longer connected directly to its counterpart input.
Thanks for joining the conversation,
Fab
The fine people at Delacor have already heard my opinion on this subject, but I’ll describe it here for posterity… 🙂
I think we all appreciate the pass-through style because it looks the cleanest. And for wires that are refnums (or classes/clusters that contain only refnums), I see no problem passing these through, as the value on the wire won’t be changed (except for the rare case of swapping out refnums). Side note: if you find yourself unbundling and rebundling refnums, as Chris shows above, then you’re kinda missing the point of how refnums work. 😉
The problem occurs when there is non-refnum data in the class or cluster, and *every* *single* *VI* that takes the class/cluster as an input also outputs the class/cluster, regardless of what actually happens in the VI. When debugging a very large application, and trying to narrow down where data is being errantly modified in the class/cluster, I have spent way too much time digging into VIs with pass-through wires that don’t modify that data. This is why I strongly suggest developers don’t put the class/cluster output on a VI unless that VI has the potential to modify the class/cluster value.
James mentions the possibility above that the interface to the VI may need to change someday if you choose not to add the class/cluster output, but then that VI ends up modifying class/cluster data in the future. I would say this situation doesn’t happen all that often, and when it does, you’re probably also adding inputs to the VI, so the interface is changing anyway. And in my experience, this situation happens far less often than the debugging situation I describe above.
Removing unnecessary pass-throughs gives us a paradox…code that is less clean, but more readable. I choose readability. 😉
Darren,
Thanks for adding your thoughts to the discussion, this is great.
I 100% agree that unbundling / rebuilding refnums is missing the point, interestingly though, when I have discussed this concept with other developers it’s references that make people feel the most nervous, and in particular, instrumentation related refnums such as VISA references. Maybe I’m asking the wrong people or maybe there was something weird going on one time.
I think it would also be ‘safer’ to suggest one way or another (wire or don’t wire) is adopted rather than changing wiring style based on datatype.
As I mentioned in the post, my view has changed recently after having to dig through far too many VIs to find the data modifier (it was my own code BTW) so I’m with you 100% on this.
Chris
It’s an interesting point and something I’ve also pondered a number of times – it always feels very wrong creating VI’s that simply have a class in and out with no pass parameters, and even more when you have a block diagram that consists of just a chain of sub VI’s.
The error thing – I’ve been caught out so many times by that where I have a piece of code that should be error agnostic (enqueing something especially) and yet doesn’t execute due to a previous error. I use error cases because it’s a nice way to bound code so all the focus is within the no error case.
Ultimately I think that as you have possibly alluded to, we’ve all be so schooled in the concept of keeping our block diagrams ultra neat and tidy and avoid spaghetti code, that sometimes we choose prettiness over something that should probably require us to unbundle only the specific values that are relevant from a class, pass them into a method and, bundle the return values afterwards which suddenly takes up probably at a minimum 3x as much real estate and really doesn’t look remotely as neat as passing the whole class, and there’s possibly a memory penalty as well.
Very tricky, and I really don’t know what’s right!
From a software design perspective it is called stamp coupling and the effects are to make the operation of a module unclear. If I had my way there would be a non-data way to connect VIs (i.e. a specific connection wire that holds no data but enforces dataflow).
Steve,
Interesting point.
HP-VEE was another graphical programming language that was fairly popular in the test & measurement community and featured a “sequence wire” that was provided as a mechanism to enforce the execution order of objects on the diagram.
Chris
I’m not 100% sure about whether it would make things better, I don’t like the impurity of passing data to enforce dataflow. I also like the clarity of knowing that if I input data it data that will be used and if I output data it’s data I need to be output.
On a similar note we use something really important like our error handling mostly to enforce dataflow.
You know my views on using stuff how it should be used and not for other nefarious purposes.
The goals of cleanliness in code and ‘at a glance’ knowledge aren’t necessarily opposed to one another. You only need to ask the question ‘How can I visually differentiate data consumers from data modifiers aside from the I/O pane’.
Consider the following
:
What if we used the VI icon to convey the information by changing the color of the bottom half of the VI to more of a ‘butter or off white color’? In this way, writers could be easily distinguished from readers.
Additionally, it might be possible to use VI scripting in conjunction with a CI server like Jenkins to apply this change as part of a locked down release procedure for your class or library.
While I haven’t had much experience in automating the VI Icons, Elaine Ramundo and I gave a presentation at the last CLA summit detailing how to strip mine VIs to find their parents, and ‘called VIs’. Thus, if you follow the practice of encapsulating your private data access for your class in an accessor VI, Identifying VIs that call the ‘write accessor’ for any given class data is trivial.
Scott,
Firstly, I did see the presentation at the last CLA summit and enjoyed it greatly. You are right of course, cleanliness in code and providing extra information should not be mutually exclusive however I think the semantics of the block diagram should not be confused. In your above suggestion the accessors are fairly easy to distinguish (I typically used the display as property node option) however are you suggesting that we apply a particular icon style to methods within the class based on how they interact with the class private data ? Would people find this more appealing that changing the wiring style I wonder ?
Thanks for joining the debate
Chris
Well, I must admit that article caused a brief doubt to me.
Then I started thinking: are the wires the preponderant information in a block diagram? To which I will negatively answer. Icons and text should be more important than wires. A meaningful icon, optionally described by a line of text will always provide me a better understanding of a diagram than some twisted wires.
My second argument would be much more pragmatic than aesthetic. Performance may be a concern with your approach. The compiler does not know what is going on in the subVI(s) unless it is inlined, so the branch will cause a copy of the object to be allocated. If by “luck” that VI has to iterate, and/or if the class is made of badly large data, I believe you got the idea.
Overall, I totally got your point and the debate it uncovers 🙂 A good post, like always I would say!
–Eric
Eric,
Firstly thanks for joining the debate and providing your insight. I really like the question you pose, “What is the preponderant information in a block diagram”. At first I reacted and thought wires but then I started thinking more about when I review somebody else’s code what are the first things I “see”. And the answer for me was “anything non-standard”, for example Express VIs in their expanded view, or VIs with the default icon so I can see why my approach may feel uncomfortable to some at first. You raise a valid point regarding the compiler and the various optimisations it makes. I feel further research may be needed!
Chris
*I 100% acknowledge that non-standard is highly subjective
“The compiler does not know what is going on in the subVI(s) unless it is inlined, so the branch will cause a copy of the object to be allocated.”
Brighter/Closer minds can confirm but I actually don’t think this is a concern. I have a feeling the compilers in place analysis flags subVI inputs about whether they need their own copy or not so this can be avoided.
I’m sure someone who reads this blog can confirm or deny this.
My understanding aligns with what James said. Branching a class/cluster wire doesn’t necessarily mean a copy is made. The compiler can figure out if the data on the wire branch is only being read and not modified, and won’t make a copy unless it needs one.
Correct. Just did a quick test here to prove it. Seems like after these years I’m still underestimating our compiler (yet I guess it’s better than the other way around) 🙂
Leaves me with my documentation point. I also fear the potential mess the branching would cause in some VIs (crossing wires, more space needed on the BD…). I know that’s trivial at this point but it may not comply with our standard style guidelines.
I feel like your approach, nonetheless correct and valid, is similar to C coders saying “Hey we don’t need brackets here because it’s only one single line of code in my if/for block”. It gives information but point is aknowledging it as a valid programming style 🙂
I like the compiler point.
I have another one:
Lets say you have a class cluster with 10 items. Some subvis manipulate some of the items but not all.
Should you separate that class cluster into several classes since they are not being used together?
If there are many and it is logically divided you should think about separating or at least putting two classes or clusters in one class.
I tend to think about dataflow design as blood veins going through my body.
Blood is going everywhere is the oxygen is being consumed where is it needed. So are the class wires.
I think that maintaining an architecture style between programmers along the years is one of the hardest aspects in programming so I wouldn’t add a view complexity that like documentation no one including the one who wrote it himself started.
taking out the output all together sounds ok but it removes the generality of the OO code.
The extra mile that LabVIEW has to make in comparison to blood is:
Each blood cell is a class (lets not talk for a minute about actors) that gets a cluster of Oxygen injected to it and after use the blood cell goes to the garbage collection in the lungs. The system starts with a number of blood cells and adds or destroys them along the way as required.
I imagine LabVIEW starting with lots of actors for its own use and for the users’ use with a state machine and data (class state or cluster) added to it. Once done the actor is free of all the occupied resources and ready for use with the threads of the cpu behaving as the ribosoms in the blood cells and the clock behaving as the heart pushing everyone forward.
I vote no to creating limbs that get blood/wire with nothing going out even if they don’t use the blood/wire. If this limb is part of the organism it should get the blood/wire.
I have just started to implement new classes I create using this technique as described by Chris and Darren, and just for good measure I am ditching the error cluster where it is clearly not needed.
This is just so liberating!
My wiring OCD is going to take some time to get used to this new look, but I really look forward to the subtle hints that not having the class (and error) passed out will give to me as a developer. With no output it is totally obvious that the data in the object is not changed by the accessor.
I am going to run with this for a while and see how it pans out. What is the worst that can happen? 🙂
Hey Neil,
I totally agree it is liberating. I must confess, old habits die hard but once you’ve had to dive several levels down to find that the cluster / class is only ever read from then it’s an easier sell.
Chris
OK, so about a month in to the experiment and I really like it.
The biggest plus point for me is that from calling code it is totally obvious that the method does not modify the class data. This is actually so useful!
Neil,
Thank you for following up and letting us know how you’re doing with the experiment. Sure, there is an initial “shock to the system” when viewing diagrams that look a little different than what we’re used to seeing but like you, I think the benefits are worth it.
Chris
After reading through this most interesting discussion I would just point out that, when developing code based on other’s (colleagues, NI, ..) classes/libraries, where you only get access to the interface and not how it is implemented, I see a direct benefit on passing through the wire on methods and adding the unbundle/bundle-functionality to eliminate the assumption that the class/library is a byValue or byReference design. If I know the wire is a byReference design there is sure no need to bundle it back again to the wire.
Marcus
Marcus, this is exactly why I like it. After dabbling in ByRef classes quite a bit I have moved back to mostly ByVal classes.
So if the developer assumes a ByVal class (for what it is worth I try and style the wire of my ByRef classes with a solid line) then if the wire comes out the method is implies it modifies the data.
No need to worry about ByRef or ByVal
If it is assumed the class is ByVal, then this
Neil, Marcus
Yes the intention was to indicate if modification of a ByVal object could be performed by a particular method by showing the pass through / output.
Makes a big difference when debugging, not having to dig several layers down in a hierarchy only to find the method only consumes the data and makes no modification to it.
Chris
I totally see the benefits on not wiring through either the class or error wire but, as Chris so elegantly said it “…old habits die hard…”, it will get hard to not go back to the “old ways” as I really like the flow of data with wiring everything.
It is with mixed emotions I will give it a try 🙂 but I look forward getting the buss on liberation.
Marcus,
I totally understand. I’m the same with the auto-wire tool, my first instinct still, after many years of trying not to, is to use the space bar to toggle tool selection. Some things must be un-learned !
Please let us know how you get on with the experiment.
Chris